
Change is constant, are you keeping up to speed? Today every organisation regardless if they are a tech organisation, is a tech organisation. Thats the reality, because their competitors are. It’s more than basic tech, AI is being infused in 2023 to amplify everyone’s secret sauce, their value proposition.
If you are trying to get on this journey, the best time to start is now.
You may know a bit about Generative AI, but are you a user or are you a builder.
Recently I constructed a three-part series for an organisation of builders. To go from zero (What is a LLM) through to Hero (SDK’s and creating applications) and in this post I want to provide additional context to help you get started building and a PDF based deck to help you deliver a similar session.
Whilst I have a GitHub repository, in this post I want to help you get started with Azure Open AI or Open AI‘s LLM’s.
NB! – This GitHub repo is inspired from the excellent Azure Open AI In A Day Workshop.
In this post we will start to build, it wont be verbose, but my aim is to get you started so that you can the Open AI Python SDK to build some simple Python based applications. These applications will cover multiple use cases.
✅Private Chat Bot 🤖😬
I will illustrate how using StreamLit, a very quick MVP protyping platform with prompt chaining, so you can build your own private LLM based chatbot.
✅ Q&A With Embeddings 🤖🔎
Want to set the LLM’s loose of your data, this script will illustrate how you can ingest txt files, perform embeddings and reference your data
✅Classification and Sentiment Analysis 🤖📚
Building on embeddings, we will leverage Keras to create clusters based on Kaggle’s top 10,000 movies. Once we have these clusters, we’ll use a prompt to extract the topics from each cluster.
Talk is cheap, show me the code
All code snippets can be found in my GitHub Repo at https://github.com/baldacchino/AzureOpenAI-LetsBuild.
The first thing I suggest you do is to perform a git clone of the repo.
git clone https://github.com/baldacchino/AzureOpenAI-LetsBuild.git
This will result in the repo being cloned.
root@Baldacchino-SurfaceLaptop4:~# git clone https://github.com/baldacchino/AzureOpenAI-LetsBuild.git
Cloning into 'AzureOpenAI-LetsBuild'...
remote: Enumerating objects: 129, done.
remote: Counting objects: 100% (22/22), done.
remote: Compressing objects: 100% (15/15), done.
remote: Total 129 (delta 9), reused 6 (delta 6), pack-reused 107
Receiving objects: 100% (129/129), 257.18 KiB | 1.20 MiB/s, done.
Resolving deltas: 100% (41/41), done.
root@Baldacchino-SurfaceLaptop4:~#
In order to be able to execute this code we need the following installed
✅ Python 3
✅ Environment file with Azure Open AI credentials (.env file)
✅ Pip3
✅ The following modules installed (pip3 install -r requirements.txt). This can be found in the scripts folder
✅ Azure Open AI API-Key
✅ Following models deployed (gpt-35-turbo | code-davinci-002 | text-davinci-003 | text-embedding-ada-002)
✅ Recommendation you use WSL2 (Windows SubSystem For Linux) or a Linux based OS. This will also work under Windows but your mileage may vary.
Your Environment
My recommendation is you use a Linux based OS or Windows Subsystem For Linux with Visual Studio Code.
In the screenshots I am using both WSL with a remote connection to my WSL installation.
Installing requirements
I am going to assume you have installed Python 3 installed and PIP. We need to install various Python modules which can be found in the scripts folder.
pip install -r requirements.txt
Which will result in output similar to below, note this is truncated.
Collecting azure-identity==1.6.0
Using cached azure_identity-1.6.0-py2.py3-none-any.whl (108 kB)
Collecting streamlit==1.18.1
Using cached streamlit-1.18.1-py2.py3-none-any.whl (9.6 MB)
Collecting openai>=0.27.1
Downloading openai-0.27.8-py3-none-any.whl (73 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 73.6/73.6 KB 2.5 MB/s eta 0:00:00
Collecting python-dotenv==0.21.0
Using cached python_dotenv-0.21.0-py3-none-any.whl (18 kB)
Collecting numpy
Downloading numpy-1.24.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (17.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 17.3/17.3 MB 11.0 MB/s eta 0:00:00
Collecting pandas
Downloading pandas-2.0.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (12.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 12.3/12.3 MB 10.8 MB/s eta 0:00:00
Collecting matplotlib==3.6.3
Using cached matplotlib-3.6.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (11.8 MB)
Collecting plotly==5.12.0
Using cached plotly-5.12.0-py2.py3-none-any.whl (15.2 MB)
Collecting scipy==1.10.0
Using cached scipy-1.10.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (34.4 MB)
Collecting scikit-learn==1.2.0
Using cached scikit_learn-1.2.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (9.5 MB)
Collecting tenacity
Using cached tenacity-8.2.2-py3-none-any.whl (24 kB)
Collecting tiktoken==0.3.0
Using cached tiktoken-0.3.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.6 MB)
Collecting llama-index==0.4.33
Using cached llama_index-0.4.33-py3-none-any.whl
Collecting langchain==0.0.129
Using cached langchain-0.0.129-py3-none-any.whl (467 kB)
Collecting faiss-cpu
Using cached faiss_cpu-1.7.4-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (17.6 MB)
Collecting cryptography>=2.1.4
Downloading cryptography-41.0.1-cp37-abi3-manylinux_2_28_x86_64.whl (4.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.3/4.3 MB 10.2 MB/s eta 0:00:00
Defining Azure Open AI EndPoint & Deploying models
We do not want to set hard coded credentials in code, so we will use an .env file. You could isloate this further by using a solution such as Azure KeyVault.
In the scripts folder, nano and create a file called ‘.env’ and place the following strings in this file, replace the value with your key and endpoint.
OPENAI_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
OPENAI_API_BASE=https://your-end-poiunt.openai.azure.com/
Ensure the following models are deployed ( gpt-35-turbo | code-davinci-002 | text-davinci-003 | text-embedding-ada-002 ) and you have given them their default names. You can name differently, but just note you will need to modify the scripts. accordingly
Testing
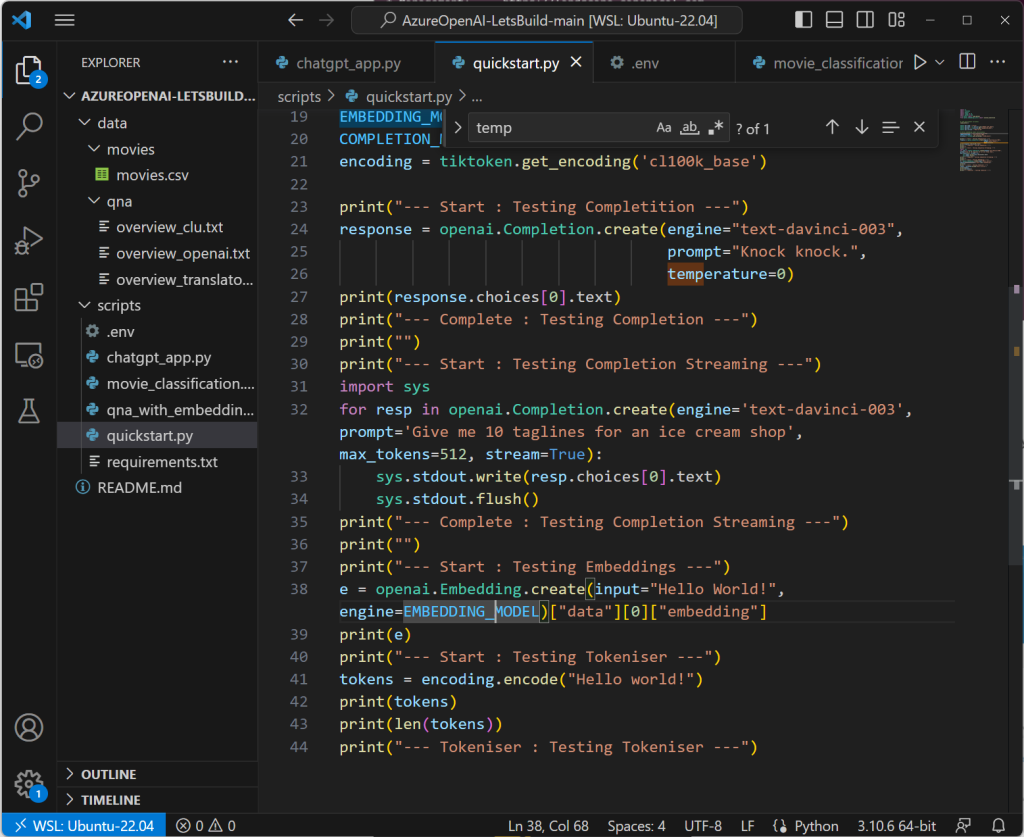
In order to validate everything is in order, execute the quickstart.py file, which will test all the basics from pip modules through to Azure Open AI.
import os
import tiktoken
import openai
import numpy as np
import pandas as pd
from dotenv import load_dotenv
from openai.embeddings_utils import cosine_similarity
# Load environment variables
load_dotenv()
openai.api_type = "azure"
openai.api_base = os.environ.get("OPENAI_API_BASE")
openai.api_key = os.environ.get("OPENAI_API_KEY")
openai.api_version = "2022-12-01"
# Define embedding model and encoding
EMBEDDING_MODEL = 'text-embedding-ada-002'
COMPLETION_MODEL = 'text-davinci-003'
encoding = tiktoken.get_encoding('cl100k_base')
print("--- Start : Testing Completition ---")
response = openai.Completion.create(engine="text-davinci-003",
prompt="Knock knock.",
temperature=0)
print(response.choices[0].text)
print("--- Complete : Testing Completion ---")
print("")
print("--- Start : Testing Completion Streaming ---")
import sys
for resp in openai.Completion.create(engine='text-davinci-003', prompt='Give me 10 taglines for an ice cream shop', max_tokens=512, stream=True):
sys.stdout.write(resp.choices[0].text)
sys.stdout.flush()
print("--- Complete : Testing Completion Streaming ---")
print("")
print("--- Start : Testing Embeddings ---")
e = openai.Embedding.create(input="Hello World!", engine=EMBEDDING_MODEL)["data"][0]["embedding"]
print(e)
print("--- Start : Testing Tokeniser ---")
tokens = encoding.encode("Hello world!")
print(tokens)
print(len(tokens))
print("--- Tokeniser : Testing Tokeniser ---")
Executing will result in similar output that tests ‘Completion’, ‘Streaming’, ‘Embeddings’ and ‘Tokeniser’. Again truncated, this time in the embeddings section.
root@Baldacchino-SurfaceLaptop4:/mnt/c/Scripts/MYOB-Session3-Code/AzureOpenAI-LetsBuild-main/scripts# python3 quickstart.py
--- Start : Testing Completition ---
Knock Knock
Who's there?
Boo.
Boo who?
--- Complete : Testing Completion ---
--- Start : Testing Completion Streaming ---
1. Get Your Scoop On!
2. Create Your Own Sundae!
3. Fill Your Cone with Fun!
4. Treat Yourself with Ice Cream!
5. Deliciously Cool Treats!
6. Refresh Your Sweet Tooth!
7. Enjoy a Cool Thrill!
8. All the Chills You Need!
9. Deliciously Smooth and Creamy!
10. Freeze Your Sweet Tooth!
--- Complete : Testing Completion Streaming ---
--- Start : Testing Embeddings ---
[0.0023968014866113663, 0.0003746475849766284, -0.0021421904675662518, -0.025725144892930984, -0.011554940603673458, 0.0009909399086609483, -0.0146354204043746, 0.003445107489824295, 9.989947284338996e-05, -0.027736887335777283, 0.02377627044916153, 0.0050042071379721165, -0.027636300772428513, -0.01019072812050581, 0.007789211813360453, 0.011680674739181995, 0.024995889514684677, -0.014145057648420334, 0.007342856843024492, 0.009662645868957043, -0.007078815717250109, 0.008518468588590622, 0.010310175828635693, 0.005815190263092518, -0.0061169518157839775, 0.0019190128659829497, 0.004884759895503521, -0.01886007748544216, 0.03756927326321602, -0.024115752428770065, 0.016043638810515404, -0.01224019005894661, -0.0031323444563895464, -0.024505527690052986, 0.009769519791007042, -0.011831555515527725, 0.0027504279278218746, -0.012485370971262455, 0.015301809646189213, -0.018558315932750702, 0.008669348433613777, 0.009813526645302773, 0.0048879035748541355, -0.01362954918295145, -0.040788061916828156, 0.016320252791047096, 0.0021201870404183865, -0.017602737993001938, -0.005287108477205038, 0.021148433908820152, 0.028893638402223587, -0.0010734527604654431, -0.01208930928260088, 0.002076180186122656, -0.013893590308725834, -0.003517404431477189, -0.03759441897273064, 0.024404939264059067, 0.028340408578515053, -0.02655498869717121, 0.01332778763025999, 0.014019324444234371, -0.01098285149782896, 0.0036242781206965446, -0.00899625662714243, 0.005978644359856844, 0.011290899477899075, 0.011140018701553345, -0.007147969212383032, 0.02655498869717121, 0.02118615433573723, -0.00494762696325779]
--- Start : Testing Tokeniser ---
[9906, 1917, 0]
3
--- Complete : Testing Tokeniser ---
Boiler Plate 1 – ChatBot with Prompt Chaining🤖😬
This is a great example of prompt chaining to create a private version of ChatGPT. With the Python module tiktoken you can easily deduce and get an understanding of cost throughout the conversation, along with the ability to change the system message. Could you make it talk like a pirate, sure. Have a poke around with the code, change the temperature (0 is Boolean up to 1 being very creative) and just have some fun.
Execute this code via streamlit
streamlit run chatgpt_app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://172.26.106.84:8501
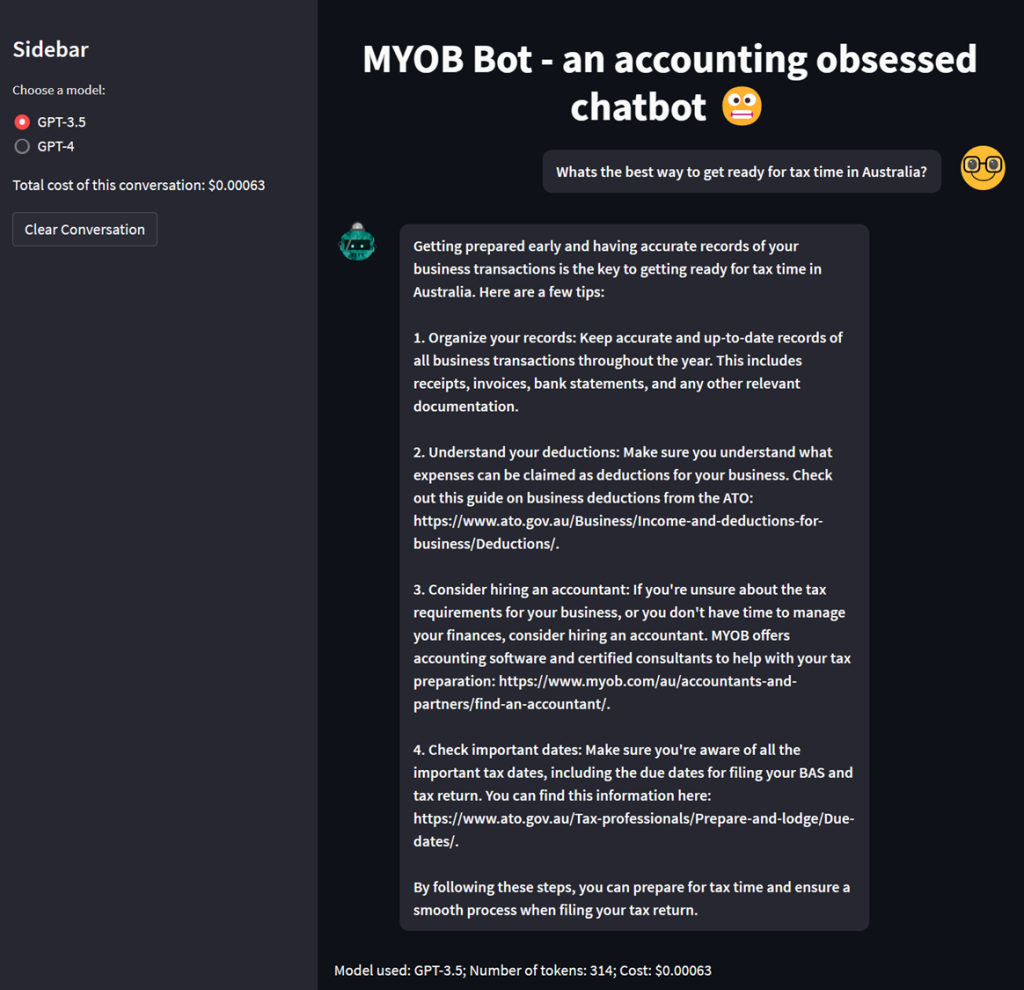
Boiler Plate 2 – Q&A With Embeddings🤖🔎
Want to be able to set GPT loose on your own data to extract value. In this snippet of code, we load in various txt files from the data directory, perform embeddings on the documents (illustrating the cost along the way) before passing in a prompt and having GPT provide us an answer from the most relevant document.
All websites today perform search, and pretty rudimentary. If you have semantic search on your website, this is going to provide you a much richer end-user experience than a Lucene based or similar engine. This example walks you through ingesting txt files, but if could very much be PDF’s, data from a NoSQL or RDMS
import os
import json
import tiktoken
import openai
import numpy as np
from dotenv import load_dotenv
from openai.embeddings_utils import cosine_similarity
from tenacity import retry, wait_random_exponential, stop_after_attempt
# Load environment variables
load_dotenv()
# Configure Azure OpenAI Service API
openai.api_type = "azure"
openai.api_version = "2022-12-01"
openai.api_base = os.getenv('OPENAI_API_BASE')
openai.api_key = os.getenv("OPENAI_API_KEY")
# Define embedding model and encoding
EMBEDDING_MODEL = 'text-embedding-ada-002'
EMBEDDING_ENCODING = 'cl100k_base'
EMBEDDING_CHUNK_SIZE = 8000
COMPLETION_MODEL = 'text-davinci-003'
# initialize tiktoken for encoding text
encoding = tiktoken.get_encoding(EMBEDDING_ENCODING)
# list all files the samples directory
samples_dir = os.path.join(os.getcwd(), "../data/qna/")
sample_files = os.listdir(samples_dir)
# read each file and remove and newlines (better for embeddings later)
documents = []
for file in sample_files:
with open(os.path.join(samples_dir, file), "r") as f:
content = f.read()
content = content.replace("\n", " ")
content = content.replace(" ", " ")
documents.append(content)
# print some stats about the documents
print(f"Loaded {len(documents)} documents")
for doc in documents:
num_tokens = len(encoding.encode(doc))
print(f"Content: {doc[:80]}... \n---> Tokens: {num_tokens}\n")
@retry(wait=wait_random_exponential(min=1, max=20), stop=stop_after_attempt(6))
def get_embedding(text):
return openai.Embedding.create(input=text, engine=EMBEDDING_MODEL)["data"][0]["embedding"]
# Create embeddings for all docs
embeddings = [get_embedding(doc) for doc in documents]
# print some stats about the embeddings
for e in embeddings:
print(len(e))
# create embedding for question
question = "what is azure openai service?"
qe = get_embedding(question)
# calculate cosine similarity between question and each document
similaries = [cosine_similarity(qe, e) for e in embeddings]
# Get the matching document, in this case we just use argmax of similarities
max_i = np.argmax(similaries)
# print some stats about the similarities
for i, s in enumerate(similaries):
print(f"Similarity to {sample_files[i]} is {s}")
print(f"Matching document is {sample_files[max_i]}")
# Generate a prompt that we use for completion, in this case we put the matched document and the question in the prompt
prompt = f"""
Content:
{documents[max_i]}
Please answer the question below using only the content from above. If you don't know the answer or can't find it, say "I couldn't find the answer".
Question: {question}
Answer:"""
# get response from completion model
response = openai.Completion.create(
engine=COMPLETION_MODEL,
prompt=prompt,
temperature=0.7,
max_tokens=500,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=None
)
answer = response['choices'][0]['text']
# print the question and answer
print(f"Question was: {question}\nRetrieved answer was: {answer}")
Execute this code with Python3
python3 qna_with_embeddings.py
Loaded 3 documents
Content: # What is conversational language understanding? Conversational language unders...
---> Tokens: 1341
Content: # What is Azure OpenAI? The Azure OpenAI service provides REST API access to Op...
---> Tokens: 1891
Content: # What is Azure Cognitive Services Translator? Translator Service is a cloud-ba...
---> Tokens: 739
1536
1536
1536
Similarity to overview_clu.txt is 0.7739850962131803
Similarity to overview_openai.txt is 0.8674998947964985
Similarity to overview_translator.txt is 0.7914908142869009
Matching document is overview_openai.txt
Question was: what is azure openai service?
Retrieved answer was: Azure OpenAI Service provides REST API access to OpenAI's powerful language models including the GPT-3, Codex and Embeddings model series. Users can access the service through REST APIs, Python SDK, or our web-based interface in the Azure OpenAI Studio.
Boiler Plate 3 – Classification and Sentiment Analysis 🤖📚
In this script, we use a subset of the Top 10000 Popular Movies Dataset to calculate embeddings on movie descriptions and then apply kmeans to find similar clusters. Once we have these clusters, we’ll use a prompt to extract the topics from each cluster.
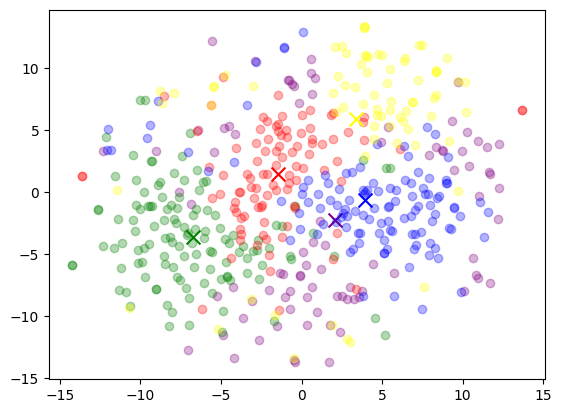
Given Microsoft’s Responsible AI practices I have selected (see movies.csv) all comedy movies to avoid taglines which trip a content filter. Tripping a filter will result in the following error. Debugging this could probably be another blog post all together.
openai.error.InvalidRequestError: The response was filtered due to the prompt triggering Azure OpenAI’s content management policy. Please modify your prompt and retry. To learn more about our content filtering policies please read our documentation: https://go.microsoft.com/fwlink/?linkid=2198766
Execute this script with Python3
python3 movie_classification.py
(715, 12)
Test would cost $0.016750800000000003 for embeddings
(715, 1536)
Cluster 0 topics: love, family, divorce
Movies from cluster 0: Guess Who, Trainwreck, In Her Shoes, Wedding Crashers, After Hours, Morning Glory, Isn't It Romantic, The Family Stone, Meet the Fockers, My Best Friend's Wedding, Click, Bridget Jones's Diary, Mrs. Doubtfire, Nappily Ever After, The Farewell, Punch-Drunk Love, City Lights, The Switch, Confessions of a Shopaholic, The Big Sick, The Wedding Planner, Major League, The Upside, Splash, Definitely, Maybe
================
Cluster 1 topics: Family, love, comedy.
Movies from cluster 1: Yours, Mine & Ours, Herbie Fully Loaded, Playing with Fire, Short Circuit, Bill & Ted Face the Music, Grown Ups 2, Dr. Dolittle 2, Beethoven, Liar Liar, Paddington, Harold & Kumar Go to White Castle, Gremlins 2: The New Batch, Christmas with the Kranks, Twins, Young Frankenstein, Borat Subsequent Moviefilm, Your Highness, The Kings of Summer, Chef, As Good as It Gets, The Dukes of Hazzard, Swiss Army Man, A Haunted House 2, American Pie Presents: Band Camp, Little Evil
================
Cluster 2 topics: Ghostbusters, Embezzle, Detective
Movies from cluster 2: Clerks, Brazil, The Waterboy, Analyze That, The Big Lebowski, Evolution, Patch Adams, In Bruges, A Fish Called Wanda, Anchorman 2: The Legend Continues, Adaptation., Tenacious D in The Pick of Destiny, Piranha 3D, White Chicks, Deuce Bigalow: Male Gigolo, Charlie Wilson's War, Meet Dave, Eddie the Eagle, Kiss Kiss Bang Bang, The Other Guys, Life of Brian, Observe and Report, Muppets Most Wanted, Police Academy 2: Their First Assignment, Zombieland
================
Summary
There you have it, simple as that. The thing is with LLM’s the barrier to entry is lower than ever. Thats a good thing. No longer do you need to be a data scientist (it still helps) to get started. Take the scripts in this boilerplate and extend upon them.
The future of AI (personal opinion) is with models that are flexible, reusable and that can be applied to just about any domain or industry task.
Foundation models are at the heart of many of the latest breakthroughs. These models are playing a major role in changing how AI systems are constructed.
Be a learn it all, get your hands dirty and build
Thanks
Shane Baldacchino