
Did you miss part one of this one of this multi part series on ‘Cost Optimisation’?
In part 2 of this multi-part blog series, I am going to cover, as per the title ‘Infrastructure’, but that’s a pretty wide remit. Stay tuned for further posts where I cover more progressive infrastructure topics, but in this post, I will cover two core building blocks that constitute the largest amounts of most cloud bills, compute and storage.
Compute in the form of servers have been around for the last 50 years (and probably will be for the next 50). Whilst today we have containers, serverless compute and many forms of persistence stores, today I will give you my thoughts on Storage (Object and Block) and VM (Virtual Machine) optimization.
Cost. I have been fortunate to work for and help migrate one of Australia’s leading websites (seek.com.au) in to the cloud and have worked for both large public cloud vendors. I have seen the really good, and the not so good when it comes to architecture.
Cloud and cost. It can be quite a polarising topic. Do it right, and you can run super lean, drive down the cost to serve and ride the cloud innovation train. But inversely do it wrong, treat public cloud like a datacentre then your costs could be significantly larger than on-premises.
If you have found this post, I am going to assume you are a builder and resonate with the developer, architect persona.
It is you who I want to talk to, those who are constructing the “Lego” blocks or architecture, you have a great deal of influence in the efficiency of one’s architecture.
Just like a car has an economy value, there are often tradeoffs. Have a low-liters per (l/100km – high MPG for my non-Australian friends), it often goes hand in hand with low performance.
A better analogy is stickers on an appliance for energy efficiency
How can we increase the efficiency of their architecture, without compromising other facets such as reliability, performance and operational overhead.
There is a lot to cover, so in this multi-part blog series I am going to cover quite a lot in a hurry, many different domains and the objective here is to give you things to take away, and if you read this series and come away with one or two meaningful cost-saving ideas that you can actually execute in your environment, I’ll personally be exceptionally that you have driven cost out of your environment
Yes, you should be spending less
In this multi part series I we’re going to cover three main domains
- Operational optimization (Part 1)
- Infrastructure optimization (Part 2)
- Architectural optimizations (Part 2 – with a demo)
With such a broad range of optimisations, hopefully something you read here will resonate with you. The idea here is to show you the money. I want to show you where the opportunities for savings exist
Public cloud if full of new toys for us builders which is amazing (but it can be daunting). New levers for all of us and with the hyperscale providers releasing north of 2000 (5.x per day) updates per day, will all need to pay attention and climb this cloud maturity curve.
Find those cost savings and invest in them, but the idea is to show you where you can find the money.
I want to make this post easy to consume, because math and public cloud can be complex at times, services may have multiple pricing dimensions.
My Disclaimer
In this post I will using Microsoft Azure as my cloud platform of choice, but the principles apply to many of the major hyper scalers (Amazon Webservices and Google Cloud Platform)
I will be using the Microsoft Azure region “Australia-East (Sydney)” because this is the region I most often use, and pricing will be in USD. Apply your own local region pricing but the concepts will be the same and the percentage savings will likely be almost exactly the same, but do remember, public cloud costs are often based on the cost of doing business in a specific geography.
Lastly, prices are a moving target, this post is accurate as of April 2022.
Storage
One of the biggest chunks of spend in the cloud other than compute is storage I want to give you a way to save money on your storage without any code changes at all.

There are two paths to head down, broadly speaking when it comes to cloud and storage, and this depends on how you use storage. Public cloud provides both object and block-based storage. In case you are trying to understand the difference between object and block-based storage, let me explain
When I grew up, my world was Microsoft DOS, then windows and a variety of Linux distributions, I stored my data on a hard disk drive, like we still do today. You have a C drive and beyond in Windows or mount (mnt) points in Linux.
Whilst the cloud provides this type of storage (block), it also ushered in a new way method of storage, object storage.
Object storage is relatively new when compared with more traditional block storage systems. In short, it is storage for unstructured data that eliminates the scaling limitations of traditional file storage. Limitless scale is the reason that object storage is the storage of the cloud. All of the major public cloud services, including Amazon (Amazon S3), Google (Google Cloud Storage) and Microsoft (Azure Blob Storage), employ object storage as their primary storage
Looking through the lens of storage, I want to provide you two mechanisms to reduce costs, both along the same lines and regardless of if this is COTS or custom code, these mechanims will allow you pull cost out of your storage tier.
Object Storage
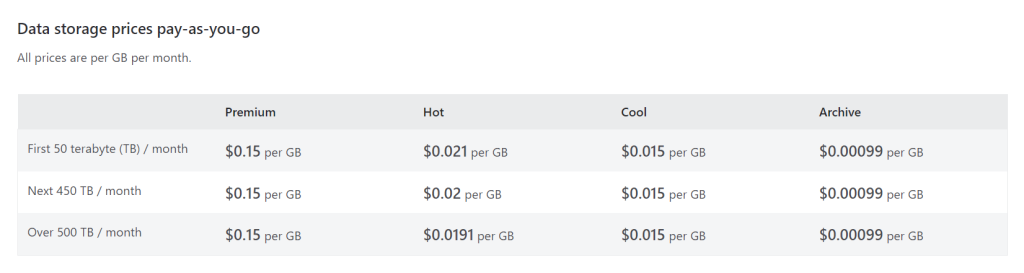
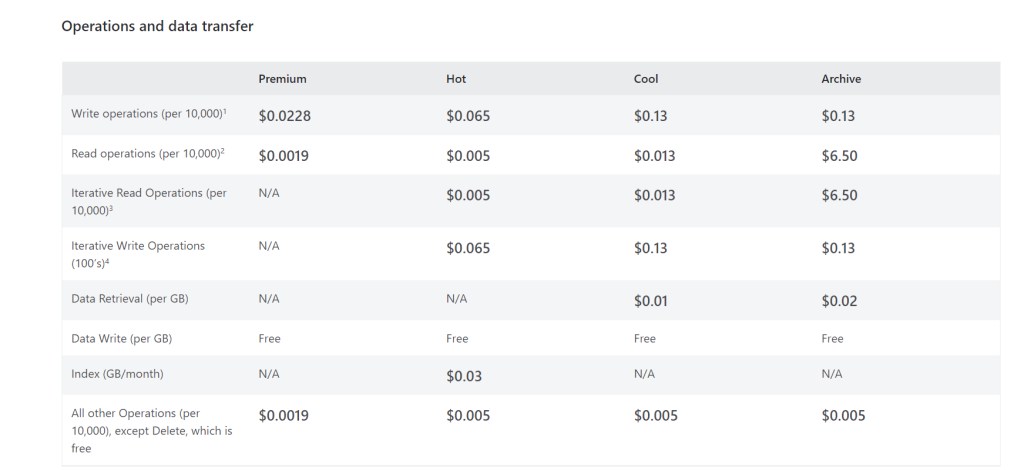
All providers provide mechanisms to tier storage and that’s what we need to do. We need to take advantage of lower price point for infrequently access data. Data is either available (hot) or its not (cold) broadly speaking. The terminology between providers is slightly different, but all offer a tier that is always available (ms access), with a lower storage cost, but a higher transaction cost. Amazon call this S3 IA (Infrequent Access), Azure calls this the Cool access tier and Google calls this nearline
We need to move the long tail of infrequently accessed data to this tier of storage, and we need to do this in a way that is automatic, using a tiering policy.
Understand the relationship between access frequency and cost at your chosen provider. A Simple way to drive down cost.
When your data is stored in a hot tier, your applications can access it immediately and whilst the hot tier is the best choice for data that is in active use, this secondary warm tier is perfect for less frequently accessed data, but note, the access fees for this tier will be substantially higher.
Let’s work a real example here.
To provide an example of this let’s imagine I have an application that allows you to rate pictures of cats and dogs.

My application has the following attributes
- Our application stores 100TB of photos
- Each photo is around 10MB in size
- Using Azure Storage in a ‘Hot’ tier it will cost $2007USD per month (April 2022, Australia-East)
- Our data has a long tail, most data after 30 days, let’s say 80% does not get accessed, it’s needed by not often.
Without any code-base changes to my application, I can use a tiering / lifecycle policy, so that older data that isn’t accessed as frequently is moved to a cheaper ‘Cool/Infrequent Access’ tier of storage but is available for immediate access.
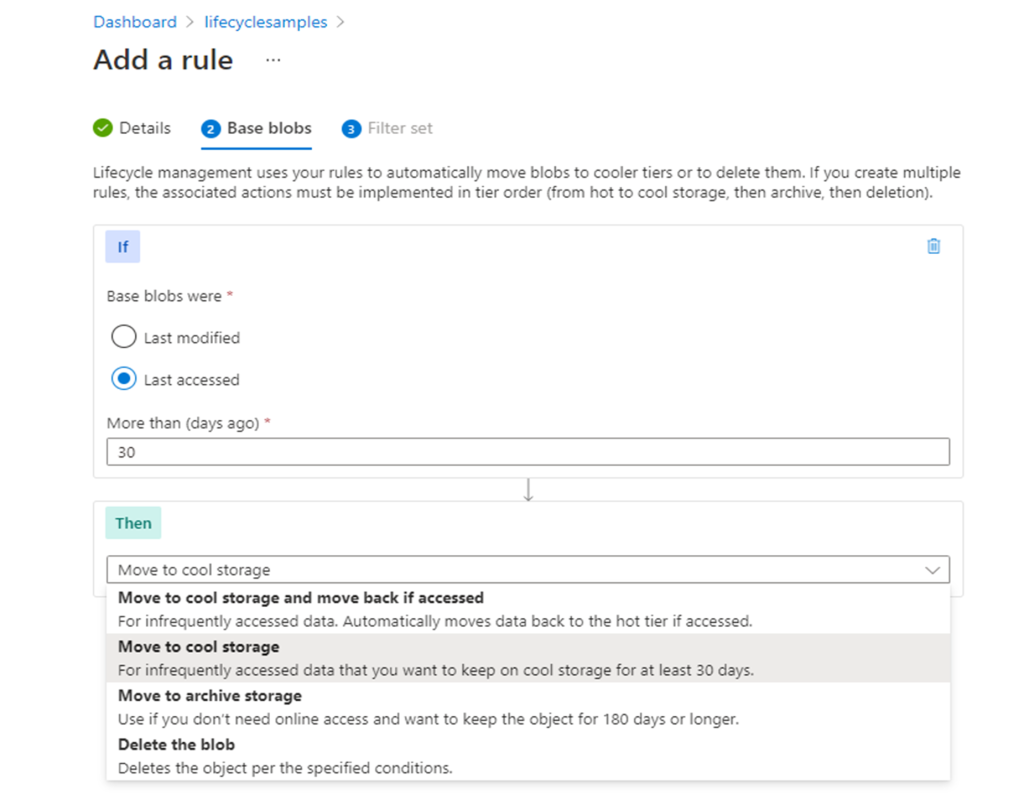
By creating a policy, which is a few clicks and no code changes I can put a tiering policy to my storage account, no code changes and now I am able to save 36% on storage costs with my new monthly cost being $1308USD.
Not bad for a few minutes of effort.
For more details and a great example of tiering through to archive and deletion see Optimize costs by automatically managing the data lifecycle – Azure Storage | Microsoft Docs
Block storage
Cloud providers will provide various types of block-based storage. From magnetic through to nVME based SSD’s, all with different performance and cost characteristics. Below is a table that illustrates types of disks available on Azure, your mileage will vary between providers but there is choice everywhere.
| Ultra disk | Premium SSD v2 | Premium SSD | Standard SSD | Standard HDD | |
|---|---|---|---|---|---|
| Disk type | SSD | SSD | SSD | SSD | HDD |
| Scenario | IO-intensive workloads such as SAP HANA, top tier databases (for example, SQL, Oracle), and other transaction-heavy workloads. | Production and performance-sensitive workloads that consistently require low latency and high IOPS and throughput | Production and performance sensitive workloads | Web servers, lightly used enterprise applications and dev/test | Backup, non-critical, infrequent access |
| Max disk size | 65,536 gibibyte (GiB) | 65,536 GiB | 32,767 GiB | 32,767 GiB | 32,767 GiB |
| Max throughput | 4,000 MB/s | 1,200 MB/s | 900 MB/s | 750 MB/s | 500 MB/s |
| Max IOPS | 160,000 | 80,000 | 20,000 | 6,000 | 2,000 |
| Usable as OS Disk? | No | No | Yes | Yes | Yes |
In this PAYG (Pay As You Go) model that is public cloud, it is imperative that we pay for what we need, not what we procure. This is not as straight forward as with ‘Object Storage’ but there are options.
My first recommendation is to understand your applications I/O profile. Monitoring platforms such as Azure Monitor, AWS Cloudwatch, Google StackDriver and along with various application performance monitoring products can alert on a plethora of I/O metrics.
Look out for I/O queues and high ms (millisecond) response times. Slow I/O can be incredibly impactful on OLTP based systems but may be transparent to end user in in highly distributed scale out systems. Know the importance of I/O on your workload.
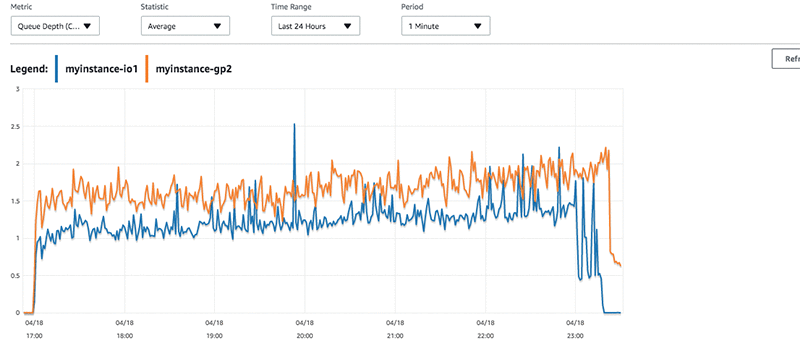
Once you understand your usage profile and your application behavior, tweak accordingly. The beauty of the cloud is that there is a means in all providers to migrate from one tier of storage to another, without loosing data.
Understand the cost to serve using premium storage vs normal and how this change in performance impacts on your application. Whilst its human nature to want the most amount of IOPS with the least amount of latency, it may not be practical from a cost to serve perspective. Understand, the tools (the block disk types) you have at your disposal and make a data driven decision on which types to use.
Here is an example on how to switch between block storage disk types in Azure using the Azure CLI. This process can also be performed in the portal of most cloud providers.
#resource group that contains the managed disk
rgName='yourResourceGroup'
#Name of your managed disk
diskName='yourManagedDiskName'
#Premium capable size
#Required only if converting from Standard to Premium
size='Standard_DS2_v2'
#Choose between Standard_LRS, StandardSSD_LRS and Premium_LRS based on your scenario
sku='Premium_LRS'
#Get the parent VM Id
vmId=$(az disk show --name $diskName --resource-group $rgName --query managedBy --output tsv)
#Deallocate the VM before changing the size of the VM
az vm deallocate --ids $vmId
#Change the VM size to a size that supports Premium storage
#Skip this step if converting storage from Premium to Standard
az vm resize --ids $vmId --size $size
# Update the SKU
az disk update --sku $sku --name $diskName --resource-group $rgName
az vm start --ids $vmId
Virtual Machines
VM’s (Virtual Machines) are ubiquitous and common in the cloud. You spin up a VM, a VMSS (Virtual Machine Scale Set) or an ASG (Autoscaling Group) and your applications runs.
Simple, but that is a thing of yesteryear. All cloud providers have over 150 different permutations of Virtual Machines with new generations and architectures launching on a regular basis (almost weekly).
Families of VM’s change from one generation to another, and new families of instance types are being launched on a regular basis. The cloud is a moving target
Here are three bits of advice when it comes to VM’s
1. Newer is better – Upgrade frequently
Within the same generation, it’s almost a given that a newer generation of an instance type is going to be cheaper whilst delivering the same levels of performance of the older generation. CPU’s and becoming more efficient with every generation. Today’s machines have either lower TDP (Thermal Design Power) or performance score than their predecessors on almost every benchmark,
Most of this is due to advancement in fabrication technologies with modern CPU’s being manufactured on 2-to-5mn process nodes.
As an example, let’s take the general-purpose compute offering in Azure the D Series and perform a cost to performance evaluation. The equivalent in AWS would be the M Series in and E Series in GCP.
| D4 V3 | D4 V5 | |
| CPU Cores | 4 | 4 |
| RAM | 16GB | 16GB |
| Processor | Intel Xeon E5-2673 v4 | Intel Xeon Platinum 82272CL |
| PassMark Single Threaded Score | 1612 | 1863 |
| Cost | $0.43USD Per Hour | $0.40USD Per Hour |
In this example, the newer instances are 14% faster and 7% cheaper than the old generation.
So please, upgrade your instances, this can be a sizable chunk of spend over a period of time, given that compute constitutes in most cases the majority of your cloud costs. You should find you need less resoucces to achieve the same outcome.
How you upgrade between instances families will vary, but this should be in many cases as simple as stopping and starting your VM in your providers web-interface, through to updating your IaC (Infrastructure As Code) scripts or adjusting your VMSS / ASG’s
2. ARM64 – The Efficiency King
ARM64 (aarch64) is an alternate architecture to X86 (Intel / AMD) that delivers significant cost savings over X86. All providers today have ARM based systems (Altera in Azure, Graviton in AWS, Tau in GCP). This architecture can be as much as 50% cheaper for the same performance of an x86 system.

Sounds too good to true, doesn’t it? Perhaps. The catch here is your workloads needs to be able to be run on an ARM64 architecture. The good news here is that the humble Raspberry Pi with its Broadcom SOC (System On Chip) over the years has done much of this heavy lifting, secondly with Apple moving to Apple Silicon this process is only accelerating.
My rule of thumb here, is your application is Open Source (MySQL, Kafka, etc) or is based on a compiled script engine (Dotnetcore, Java, Golang, Python, etc) then in 99.5% of cases, it will just work.
However, if your application is COTS based and more so if you are using Microsoft Windows, today in 2022 your mileage may vary.
Hardware review website, Anadtech performed a great write up comparing AMD and Intel’s finest against Amazons Graviton 2 processor, which is based on ARM v8 architecture. Whilst the AMD & Intel offerings win the performance crown, it’s a massacre (in favour of Graviton 2) when it comes to a cost:performance ratio.

In most providers the cost difference between ARM and x86 is a staggering 40 –> 50%!
3. Use SPOT Compute
Do you use SPOT instances? I love them, if SPOT is not part of your compute strategy, ask yourself why not.
The short of it is, providers have capacity in their facilities that goes unused. Think of this like hotel rooms, if they aren’t being used, then they are just wasted.
Providers capacity plan so you don’t need to. But it means they have a lot of capacity that at times is sitting idle. Capitalise on this idle capacity. The SPOT market price fluctuates based on demand.
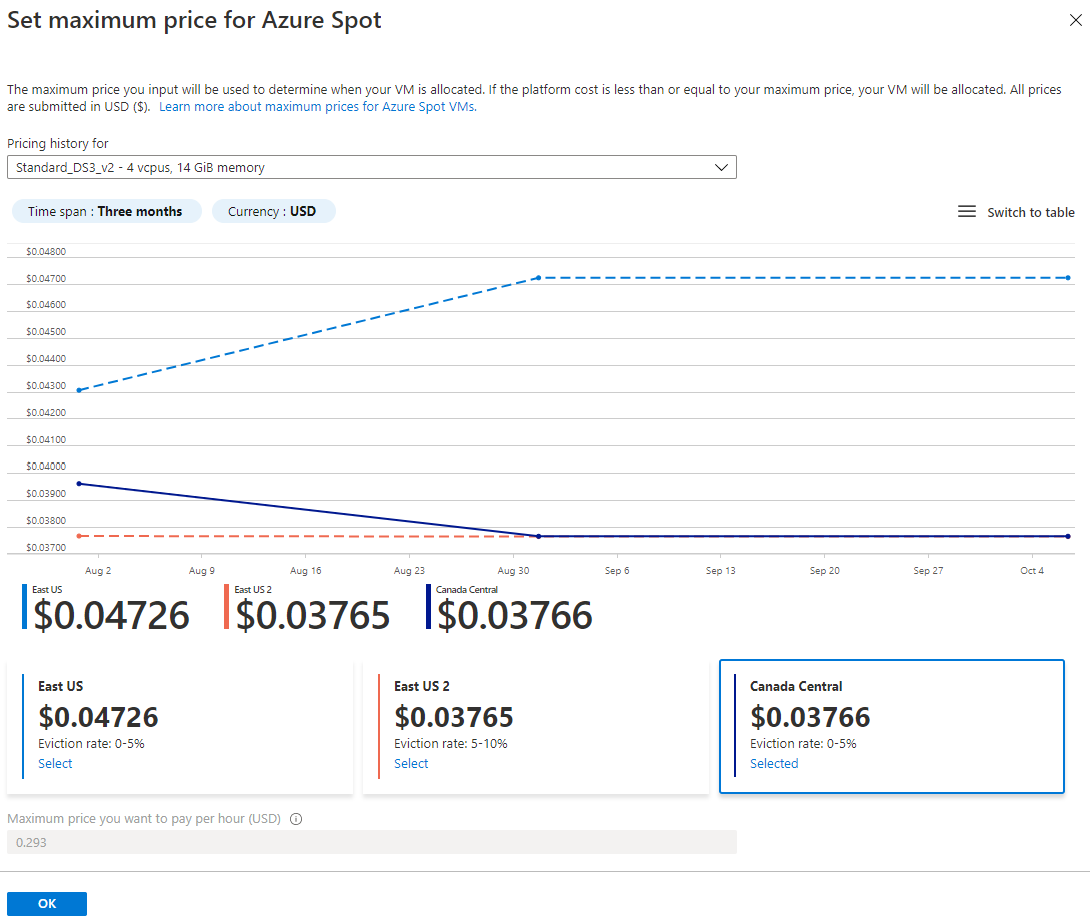
If there is low demand, the price will be low, if there is high demand the price will rise and may even equal that of the on-demand price.
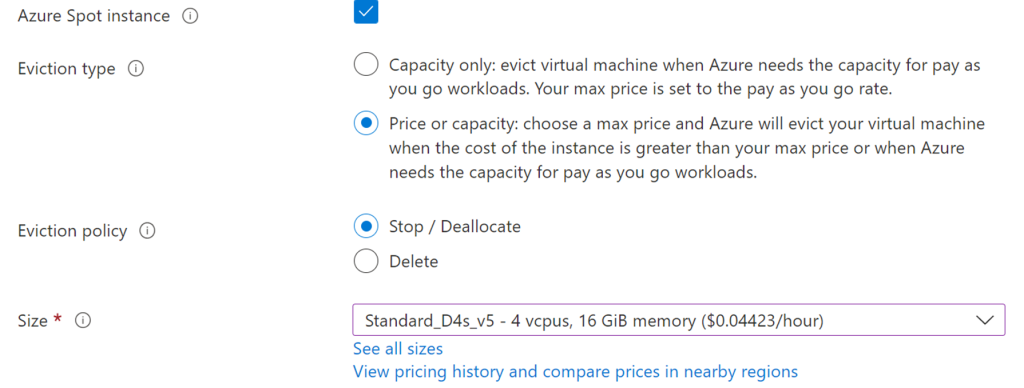
SPOT provides great value for your workloads, but for many people they’re only familiar with using them for maybe development, test some or some highly scalable and embarrassingly parallel processing type of workload. The reason for this is because SPOT instances can be revoked by a provider in a short period of time, typically with as little as a 2 minute notice.
But did you know you can use it other more applicable ways. Could it be part of your steady state workloads. Use sport as part of your VMSS and ASG’s for your Virtual Machine Scale Sets. Yes, you can combine SPOT and On-Demand instances in the same VMSS / ASG. This means your online / synchronous workloads in respect to your end-users can be hosted using SPOT compute.
The level of SPOT integration differs between providers, but in this example, we have gone are from 40 cents per hour to 4.4 cents per hours. Is the juice worth the squeeze? I sure think it is and I hope you do also.
Keep an eye on SPOT as it’s becoming more and more integrated in-to these platforms.
Before you bet the house on SPOT, to reduce the risk, have a bidding strategy. To cover your elastic workloads bid the higher than the market rate but lower than the on-demand price. One of the benefits of the way the SPOT market works is even if you bid higher than the SPOT price. You pay the prevailing rate, so if I bid $1 per hour and the prevailing rate is $0.50 per hour, I pay $0.50.
This is great, as long as I’m bidding lower than the on-demand rate and higher than a SPOT rate I’m automatically saving money of some description.
SPOT instances might not always be available, and it should just be part of puzzle that is your VM strategy.
And with that, stay tuned to part 3 where we get real and hopefully, we will cut some code.
Summary
That was a long post, and in being honest there was more I could have covered.
Public cloud brings a magnitude of opportunities to builders and architects. Are you looking for the pots of gold? They are there. Public cloud provides you a raft of new levers that you can pull, twist, pull to architect for the new world.
Climb the cloud maturity curve and achieve the same or better outcome at a lower cost.
Architectures can evolve, but it needs to make sense. What is the cost to change?
Join me in part 3 as we get deeper into Software Architectural optimisations you can make.
Shane Baldacchino
4 thoughts on “Part 2 – Infrastructure Cost Optimisation In The Cloud – Practical Design Steps For Architects and Developers”