
They are finally here. As I pen this article in September of 2022, Azure finally has ARM based (aarch64) compute to compliment the slew of x86 offerings in the form of Intel and AMD SKU’s, which all add to increase the completeness of vision within the Microsoft Cloud.
It’s not often I comment on new releases of technology. With each new generation, we might get a faster CPU or perhaps a different ML framework, it’s an evolution in many aspects and often not business differentiating. Same, same right.
Today, whilst being technology obsessed, I use a single laptop along with a 1RU NAS (x86) and a 4 x Raspberry PI 4’s (aarch64) in my rack, the latter being surprisingly capable and sips power vs. the ProLiant DL370 G9 that used to power my house. But I think what we have here is a step change in terms of efficiency (performance:watt).
With the arrival of AWS’s Graviton ARM based CPU’s, I have witnessed a huge stampede of customers from Australian Cloud Lighthouses through to the international giants of Netflix, Snapchat and more performing wholesale change of x86 (AMD / Intel) to ARM. Apple has transitioned to Apple Silicon with their M1 and now M2 CPU’s (based on an ARM), Cloudflare runs fully on ARM, stating they are now 39% more efficient, and the Raspberry PI has empowered millions worldwide with devices as little as $10 (Pi Zero W) running on an ARM architecture. Huge!
Why? It is simple. The cost to performance ratio. In Part 2 of my Cost Optimisation Series, I spoke about the use of ARM based CPU’s as a lever to pull out cost out of your environment. If you missed it, be sure to check out my tips on how you can tune cost out of your environment.
In summary, yes, you can drive out cost using Reserved Instances / Compute Savings Plans and Spot based compute, but it will only take you so far.
As a builder on cloud, ARM is another lever, to tune out cost in your environment. If you are reading this article to understand if ARM will help you reduce the cost to serve, then the summary is yes. Generally speaking, if your workload will run on the aarch64 architecture, then by and large this is true, but there are caveats, I will get to these later as for some scenarios, x86 will be cheaper per operation.
But it’s more than cost, as the world strives to decarbonize, we need to increase the efficiency of our platforms. Is this a step change?
What Was launched?
So firstly, what was launched. A full press release can be found at https://azure.microsoft.com/en-us/blog/azure-virtual-machines-with-ampere-altra-arm-based-processors-generally-available/ but the short of it is 3 new instance families was released.
- Dpsv5 series, with up to 64 vCPUs and 4GiBs of memory per vCPU up to 208 GiBs,
- Dplsv5 series, with up to 64 vCPUs and 2GiBs of memory per vCPU up to 128 GiBs, and
- Epsv5 series, with up to 32 vCPUs and 8GiBs of memory per vCPU up to 208 GiBs.
The heart of this platform is the Ampere Altra.

In case you aren’t familiar with Ampere, Ampere Computing, founded in 2017 by former Intel president Renée James, built upon initial IP and design talent of AppliedMicro’s X-Gene CPUs, and with Arm Holdings becoming an investor in 2019, and today they offer up Neoverse-N1 server designs in the form of the Altra.
After spinning up a D4psv5 VM in Azure I can confirm the 3ghz clock speed as listed at https://docs.microsoft.com/en-us/azure/virtual-machines/dpsv5-dpdsv5-series is accurate.
I can learn a little bit more about this CPU’s architecture (L1,l2,L3 caches) by using lscpu under Ubuntu and dmidecode
The Ampere Altra is based on a Neoverse N1. CPU. For a review of the CPU in greater detail, check out the excellent review on Anandtech
baldacchino_admin@d4psv5:~$ lscpu
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: ARM
Model: 1
Model name: Neoverse-N1
Stepping: r3p1
BogoMIPS: 50.00
L1d cache: 256 KiB
L1i cache: 256 KiB
L2 cache: 4 MiB
L3 cache: 32 MiB
NUMA node0 CPU(s): 0-3
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Not affected
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Mitigation; CSV2, BHB
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp
cpuid asimdrdm lrcpc dcpop asimddp
The clock frequency is 3ghz. It is interesting why Azure is not listing the clock speed when queried via lscpu, yet for both AMD and Intel offerings, this is listed. We can use dmidecode to extract these values. With 1 thread per core, there are no SMT, I wonder how this scale, my guess is pretty well as there will be no branch predication (which can be an issue, when it goes wrong) on SMT based CPU’s.
baldacchino_admin@d4psv5:~$ sudo dmidecode -t processor | grep "Speed"
Max Speed: 3000 MHz
Current Speed: 3000 MHz
Why This Post?
Quite simply put, I want to understand the cost to serve between these new instance classes versus the AMD and Intel offerings of similar nature and help you make an informed decision if you should adopt ARM64 based machines in Azure.
In this post I will kick the tires and take a new Ampere based instance on Azure for a spin with the aim of helping you understand if these instances should form part of your cloud strategy. What are their strengths, what are their weaknesses, when are these new instances classes appropriate for you to use?
As a builder today in 2022, cloud and cost. It can be quite a polarising topic. Do it right, and you can run super lean, drive down the cost to serve and ride the cloud innovation train. But inversely do it wrong, treat public cloud like a datacenter then your costs could be significantly larger than on-premises.
Just like a car has an economy value, there are often tradeoffs. Have a low-liters per (l/100km – high MPG for my non-Australian friends), it often goes hand in hand with low performance
Can the new Ampere based instances in Azure increase the economy of my architecture?
I speak of ARM as a tool to reduce cost in my post “Infrastructure Cost Optimisation In The Cloud – Practical Design Steps For Architects and Developers” and it should be near top of mind as a means to tune out cost in your tech stack in 2022.
The Cost To Serve
Broadly speaking, cloud costs are driven by multiple dimensions, but ultimately for most vendors, it is based on the cost to serve in a specific geography. There are multiple dimensions, ranging from the capital cost of the devices, things, servers through operational costs.
There is a green aspect of these new Ampere Altra CPU’s that I want to look at. That is the TDP, or Thermal Design Power. The summary (see the link for a more detailed and accurate overview) of TDP is how much heat do these devices generate, which translates to density and cooling requirements.
Whilst Ampere have many Altra SKUs with varying frequencies and TDP’s for this processor, the TDP of these processors are all lower than the Intel and AMD offerings per core. In the table below you will see how the Ampere Altra compares to Intel, and AMD SKU’s I will be comparing against in this post from a TDP, Core, Clock Rate and Watts Per Core perspective.
| Azure SKU – CPU Architecture | Cores / Threads | Clock Rate | TDP | Watts Per Core |
| Dpsv5 – Ampere Altra Q80-30 | 80 (80 Threads) | 3.0 GHz | 210 W | 2.625W |
| Dsv5 – Intel® Xeon® Platinum 8370C (Ice Lake) | 64 (128 Threads) | 3.5 GHz | 270 W | 4.218 W |
| Dasv5 – AMD’s 3rd Generation EPYCTM 7763v | 64 (128 Threads) | 3.5 GHz | 280 W | 4.375 W |
With a lower TDP per core, it translates theoretically less heat generated and increased density per rack and less cooling. Yes, not all cores are created equal and there is a difference in performance per clock cycle, which we will get to later.
Having a lower TDP means, datacentres can significantly increase density without requiring more power and cooling. Worth noting is the CPU is only one of many parts in a server and there is no guarantee that an ARM based system will have a total overall wattage draw, but it is indicative.
Testing & Results
This is not a hardware blog, I am not a tester, but I have done my best to make this as impartial and fair as possible. I will be testing only 4vCPU and 16GB RAM instances in this post, your mileage may vary, and scaling may not be linear for larger virtual machines.
I have tried to make this as much of an apples vs apples comparison as possible and remove variables such as storage as much as possible.
What is common
- 4vCPU and 16GB of RAM.
- Premium SSD storage
- 2048 Gib
- Disk Tier p40
- Provisioned IOPS 7500
- Provisioned Throughput 250MBps
- Ubuntu 22.04 LTS
- MySQL-Server 8.0.30-0
- SysBench 1.0.18 (using system LuaJIT 2.1.0-beta3)
- Prices are accurate as of September 2022
| Instance Type | Architecture | vCPU | RAM | Cost Per Month – PAYG (US-WEST-2) |
| D4psv5 | ARM64 (Ampere Altra) | 4 | 16GB | $153.35 USD |
| D4sv5 | x86 (Intel Xeon Ice Lake) | 4 | 16GB | $192.44 USD |
| D4asv5 | x86 (AMD EPYC Milan) | 4 | 16GB | $172.39 USD |
The tests performed will target the CPU more than any other facet of the system and I will be using SysBench to perform both a heavy MySQL CPU computation test and a prime number generation test.
I chose SysBench for a few reasons.
- Sysbench is a multi-threaded benchmark tool based on luaJIT. It is the standard for MySQL benchmarks, it needs to be able to connect to the database.
- Cost, Sysbench is free. I would have liked to use SPECInt but the cost ruled this out.,
- CPU Stress testing can test single through to multi-threaded performance.
MySQL Heavy Computational Test
This post will not detail the installation and basic configuration of MySQL, the heavy SysBench computational test has an element of I/O but with all systems using Premium SSD with a tier of P40 and so little throughput required for this test, I/O was not being saturated.
I am going to run two different tests
Time 5 minutes | Target TPS 500 | Number of threads 32.
Time 5 minutes | Target TPS 750 | Number of threads 32.
In preparation I created 16 tables with 10,000 records in each table with the following commands
sysbench \
--db-driver=mysql \
--mysql-user=sbtest_user \
--mysql_password=password \
--mysql-db=sbtest \
--mysql-host=localhost \
--mysql-port=3306 \
--tables=16 \
--table-size=10000 \
/usr/share/sysbench/oltp_read_write.lua prepare
sysbench 1.0.18 (using bundled LuaJIT 2.1.0-beta3)
Creating table 'sbtest1'...
Inserting 10000 records into 'sbtest1'
Creating a secondary index on 'sbtest1'...
.
.
.
Creating table 'sbtest16'...
Inserting 10000 records into 'sbtest16'
Creating a secondary index on 'sbtest16'.
After the creation of the dataset I then tested each system with the following command.
sysbench --db-driver=mysql --mysql-user=sbtest_user --mysql_password=password --mysql-db=sbtest --mysql-host=localhost --mysql-port=3306 --tables=16 --table-size=10000 --threads=32 --time=20 --events=0 --report-interval=1 --rate=[500 or 750] /usr/share/sysbench/oltp_read_write.lua run
Which resulted in an output similar to this on each server.
$ sysbench --db-driver=mysql --mysql-user=sbtest_user --mysql_password=password --mysql-db=sbtest --mysql-host=localhost --mysql-port=3306 --tables=16 --table-size=10000 --threads=32 --time=300 --events=0 --report-interval=1 --rate=500 /usr/share/sysbench/oltp_read
_write.lua run
sysbench 1.0.18 (using system LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 32
Target transaction rate: 500/sec
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
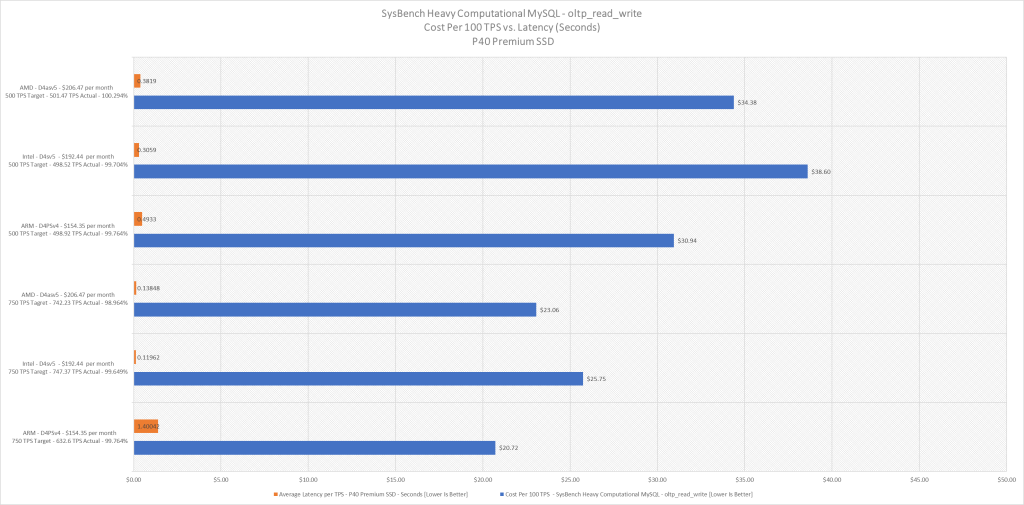
| Cost Monthly | Target TPS | TPS Actual | TPS Att | Latency (avg) | Latency (95th %) | |
| ARM – D4psv4 | $154.35 | 500 | 498.82 | 99.76% | 49.33ms | 106.75ms |
| Intel – D4sv5 | $192.44 | 500 | 498.52 | 99.70% | 30.59ms | 62.19ms |
| AMD – D4asv5 | $172.39 | 500 | 501.47 | 100.29% | 38.19ms | 74.46ms |
| ARM – D4psv4 | $154.35 | 750 | 747.63 | 99.68% | 1400.42ms | 2985.89ms |
| Intel – D4sv5 | $192.44 | 750 | 747.37 | 99.64% | 119.62ms | 450.77ms |
| AMD- D4asv5 | $172.39 | 750 | 747.62 | 98.68% | 138.48ms | 539.71ms |
CPU Prime Number Generation
This test calculates prime numbers up to 10000 using a set number of threads.
sysbench cpu --threads=4 run
sysbench cpu --threads=1 run
| Events Per Second | Threads | |
| ARM – D4psv4 | 140528 | 4 |
| Intel – D4sv5 | 62357 | 4 |
| AMD – D4asv5 | 82864 | 4 |
| ARM- D4psv4 | 35175 | 1 |
| Intel – D4sv5 | 29420 | 1 |
| AMD – D4asv5 | 36830 | 1 |
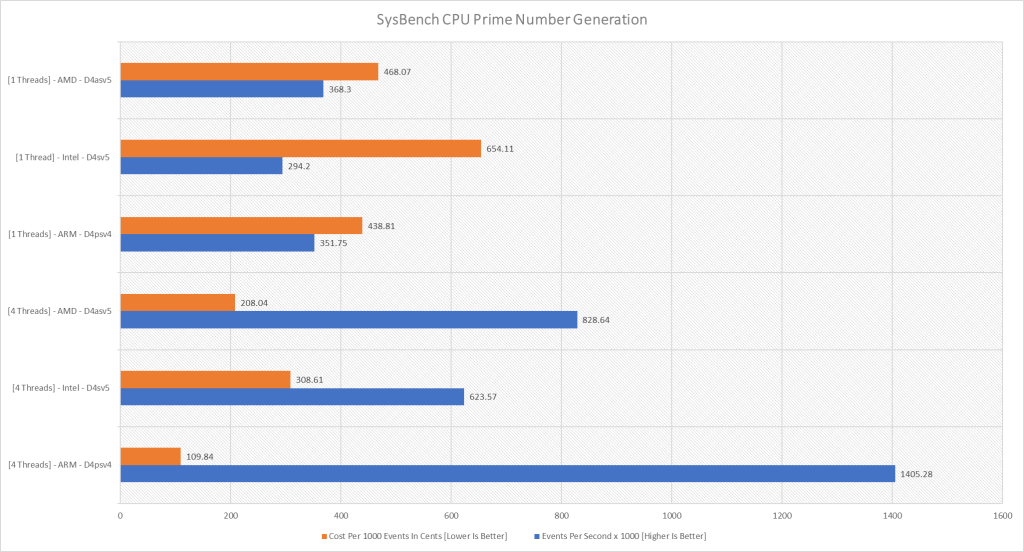
Single threaded performance of Ampere Altra trails both AMD and Intel variants, but scales almost linearly whilst both x86 variants do not. Worth noting there is no form of SMT on these processors, ensuring you will not receive virtualized cores.
What Workloads Will Work On This Architecture?
Can I run all my workloads on aarch64? No. Your software will need to be compiled for aarch64. But a good rule of thumb is, most OSS (Open Source Software) will run.
The humble Raspberry PI is ARM64 based and has driven much of this heavy lifting from an industry perspective and Apple have just accelerated this with their M1 series. If it runs on a Raspberry Pi then it will run on these new instance types (rule of thumb).
Most COTS and Windows Server, as of the time of this post cannot use aarch64, but watch this space and check with your vendor, as with every passing day more and more applications are finding their way to aarch64.
If you are running a compiled script engine (Python, C++, Node, PHP, Java, DotNetCore etc) or a stack that has been ported then there is typically little to no effort required to port over, it may just be a redeployment.
Calculating The Cost To Serve
Testing has shown that these systems are more or less on par with x86 offering in Azure in terms of performance. I must stress, I have performed limited testing here, so please do you own due diligence. The tests I performed however should be representative of holistic and general system performance.
But does this mean that you should adopt these? Broadly speaking, if you can (see above) then yes! Unless there is a reason why you cannot adopt these instances, or performance is not within the same ballpark as the x86 offerings for your given workload, my recommendation is that the price to performance ratio benefit should make Ampere based instances in Azure your default choice.
| CPU – Prime 4 Threads [Cost vs Events Per Second] | CPU – Prime 1 Thread [Cost vs Events Per Second] | Heavy Computational MySQL 750 TPS [Cost vs TPS Attained] | Heavy Computational MySQL 500 TPS [Cost vs TPS Attained] | |
| Intel D4sv5 vs ARM D4psv4 | 64.4% Better $ to Performance Ratio Winner ARM D4psv4 | 32.9% Better $ to Performance Ratio Winner ARM D4psv4 | 19.8% Better $ to Performance Ratio Winner ARM D4psv4 | 19.8% Better $ to Performance Ratio Winner ARM D4psv4 |
| AMD – D4asv5 vs ARM D4psv4 | 47.2% Better $ to Performance Ratio Winner ARM D4psv4 | 6.2% Better $ to Performance Ratio Winner ARM D4psv4 | 9.9% Better $ to Performance Ratio Winner ARM D4psv4 | 10.4% Better $ to Performance Ratio Winner ARM D4psv4 |
If I had to codify my thought process it would be something like this
if software_architecture == "aarch64":
if cost_to_serve_on_aarch64 < x86:
print("Use Ampere based VM")
else:
print("Use x86 based VM")
Lets Talk About Extensions
Neoverse N1 is RISC architecture, and as such it lacks many hardware based extensions found on both Intel and AMD CISC based architectures. Below I ran lscpu on the Intel based VM and on this ARM based VM. You can just see the rich heritage the x86 platform with its CISC (Complex Instruction Set Computing) has, there are more processor supplementary extensions than you can poke a stick at.
fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca c
mov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx p
dpe1gb rdtscp lm constant_tsc rep_good nopl xtopology tsc_
reliable nonstop_tsc cpuid aperfmperf pni pclmulqdq vmx ss
se3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_de
adline_timer aes xsave avx f16c rdrand hypervisor lahf_lm
abm 3dnowprefetch invpcid_single tpr_shadow vnmi ept vpid
ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms in
vpcid rtm avx512f avx512dq rdseed adx smap avx512ifma clfl
ushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsa
vec xgetbv1 xsaves avx512vbmi umip avx512_vbmi2 gfni vaes
vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq la57
rdpid fsrm arch_capabilities
Now let’s look at the ARM based VM’s supplementary extensions
fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp a simdhp
cpuid asimdrdm lrcpc dcpop asimddp
Extensions increase the usefulness and performance of the processor design, allowing it to compete more favorably with competitors and giving consumers a reason to upgrade, while retaining backwards compatibility with the original design.
AVX-512 as an example, is a relatively modern extension for accelerating cryptographic and deep learning workloads. This is just one of many workloads that may result in a performance penalty with aarch64 and as part of sound performance testing, you should always benchmark your workloads to understand how they behave (and the cost to serve) on a given architecture.
Summary
Driving down the cost to serve is an evolutionary process, iterative and continuous. The Azure cloud in past 12 months has released almost 5 updates per day and its feature and service changes like ARM based instances that enable you to continue to reduce the cost to serve.
Should AMD and Intel should be worried? ARM world dominance is far from certain, but research shows ARM is on track to a 22% enterprise market share by 2025. Intel’s failed acquisition of SiFive, has put a dent on their ARM play. What will the next generation of XEON and EPYC processors look like? Will they be more efficient per watt.
Let me be clear, I am not anti-x86 but I am about reducing the cost to serve and reducing the carbon footprint of the services that power of lives. Yes, our lifestyle today has a cost, and the cost of these services can have a negative impact on the environment.
Compute resources are being consumed at an exponential rate, 10% of the world electricity consumption! Can ARM play a role to decarbonize the world, what role can you play? Will Intel and AMD release CPU’s with a higher performance to watt ratio?
Climb the cloud maturity curve and achieve the same or better outcome at a lower cost with these new instance types.
Architectures can evolve and the emergence of ARM based instances are like taking a ladder to help you climb the cloud maturity curve in a game of snakes and ladders. Instance types based on Ampere ARM CPU’s are one of the easiest ways you can leverage cloud to drive out cost out of your technical stack and I am thrilled Azure has joined the ARM race.
Shane Baldacchino