
Did you miss part one and part two of this this multi part series on ‘Cost Optimisation’?
In part 3 of this multi-part blog series, I am going to cover, as per the title ‘Architectural Cost Optimisation’.
In prior posts I have spoken about foundational primitives, what you can change and tune in the cloud without changing your applications.
But you know what? Architectures can evolve, and they should evolve fueled by business efficiency and cost savings.
If you are an architect or developer joining us today, you are unbelievably lucky because with every day you get new levers to pull.
The major two Hyperscalesrs (Azure and AWS) released more than 2000 new feature updates and or new services in 2022.
You can pull them up, you can pull them down, it is all about choice. But isn’t it cool with intelligent decisions; you can pull different levers and get different outcomes.
You can do code changes. That is often the best way to fix problems in many cases. I am sure we could relate to the number of times we have spoken to a customer or an internal stakeholder about an application that runs terribly and rather than fix it, we are using infrastructure as a band aid.
In part 3 of this series, I am going to illustrate that perhaps more than ever you should just fix that application in the first place, climb the cloud maturity curve and challenge yourself, just note there are always architectural trade-offs to be made.
Today there are way more decisions than you ever had to make before, on the one hand that’s challenging because you need to learn more but the flip side is it’s great because you’ve got more choice and you can make better more finely honed decisions and you can test them in real time to see if they make sense.
With public cloud you’re not sitting there twelve months before deployment going, I think if I use this kind of approach, it’ll be ok.
You can say well I tried that, it didn’t work, and I’m going to spend a week and change it to something completely different and it’s okay. It really is okay, so let’s talk about some of those levers and some of those tricks you can use to reduce cost by changing your architecture.
Eliminate Your Web Server Tier and use Static Web Apps

Getting rid of your webservers. Has that thought ever crossed your mind?
I am sure everyone here has webservers that they manage but do you really need them? What are they really doing?
These days with modern web frameworks, you can eliminate your web-server tier. They are costly, increase your security surface attack area. With the era of compute at the edge (Azure Front Door / CloudFlare Workers / Akamai Edge Workers / CloudFront Functions) , are you’re really just spending most of your time patching feeding upgrading and looking after them.
A modern approach to take is static web-apps.

I am going to say, it is kind of a bad name (personal opinion) as its not that static. Its 2023. The world runs on Javascript (ECMA) based framework and you can do a lot of things.
You make API calls, invoke an SDK (Azure and AWS JavaScript), call API Gateways (Azure API-M and Amazon API Gateway) and more.
Static Web Apps supports JavaScript and TypeScript front-end apps including those developed with popular frameworks such as Vue.js, React, Angular and more. SPA’s or single page apps are fast becoming the norm in cloud based development.
In the thread of this multi-part series, elevate the story from high to low. You’re not patching servers, there’s no scaling rules to worry about, it just works what does that cost me to run
| Average Object Per Page | 150 |
| Average Page Size | 2MB |
| Page Views Per Day (GET) | 100,000 (450,000,000 per month) |
| Data Transfer Egress Per Month | 5.8TB |
| Total Cost (Azure Static Web Apps) | $1,176USD (Australia-East | December 2022) |
| D4v5 – Qty of 6 | $1,538USD (Australia-East | December 2022) |
As we mentioned earlier, what does it cost to administer which I didn’t calculate. I’m not patching web servers anymore, I’m not doing capacity planning and am not having to worry so much about my security scanning because the pipeline is cleaner and simpler.
Static WebApps, I challenge everyone here today to take a look and consider the possibilities if you truly need those Apache, NginX, or IIS machines around?
Database Economic Architectures
Not everything is SQL or NoSQL.
You may have heard of the proverb, “all roads lead to Rome”. In the application world Rome is often your relational database. Your goal as a modern cloud architect is to reduce CRUD calls to their minimum.
One approach to doing this is to use a noSQL database and caching as a mechanism not only bring speed, but to drive out cost.
If you look at any web scale application they have caching everywhere. It is the new normal and we need to take advantage of it more. Do not confuse your transactional database with your analytical database, there is a reason why a reporting service exists and why a relational database engine exists. For the same reasons you would seperate these workloads quite often their will be hotspots in your databases and these are the giveaways where either a rafactorisation or another more suitable tool can be used.
I am not saying relational database performs are terrible, let’s move the whole thing over to Cosmos DB, MongoDB, DynamoDB or similar, because their are pros and cons to every solution.
Caching the right parts of your application in an in memory cache or using noSQL can be a game changer.
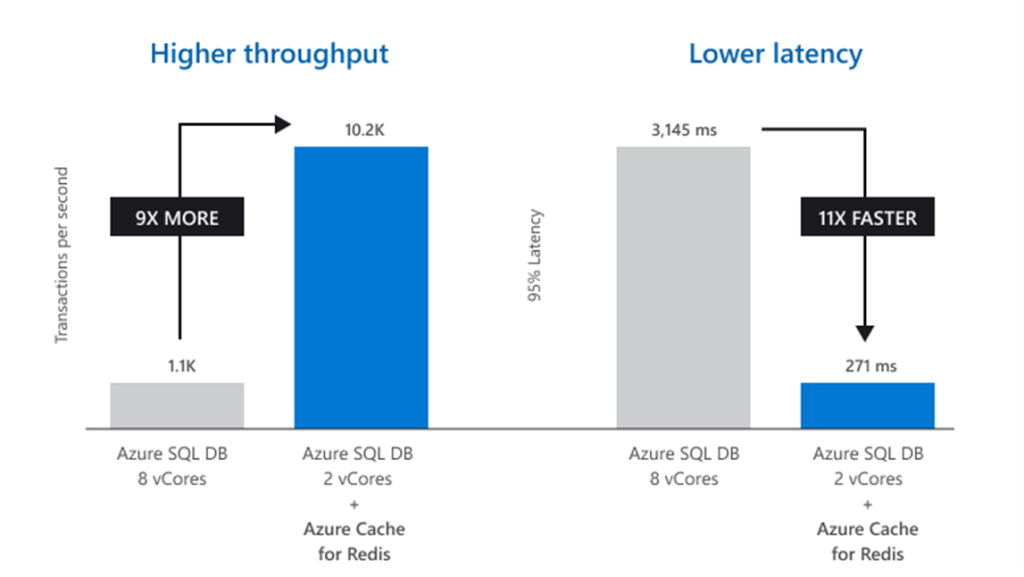
Whilst this diagram is from Microsoft, I want to talk to you about my time at seek.com.au with around 20k concurrent users, storing session state in a relational database. It became a costly exercise in ensuring the relational database could support such high user concurrency with low latency.
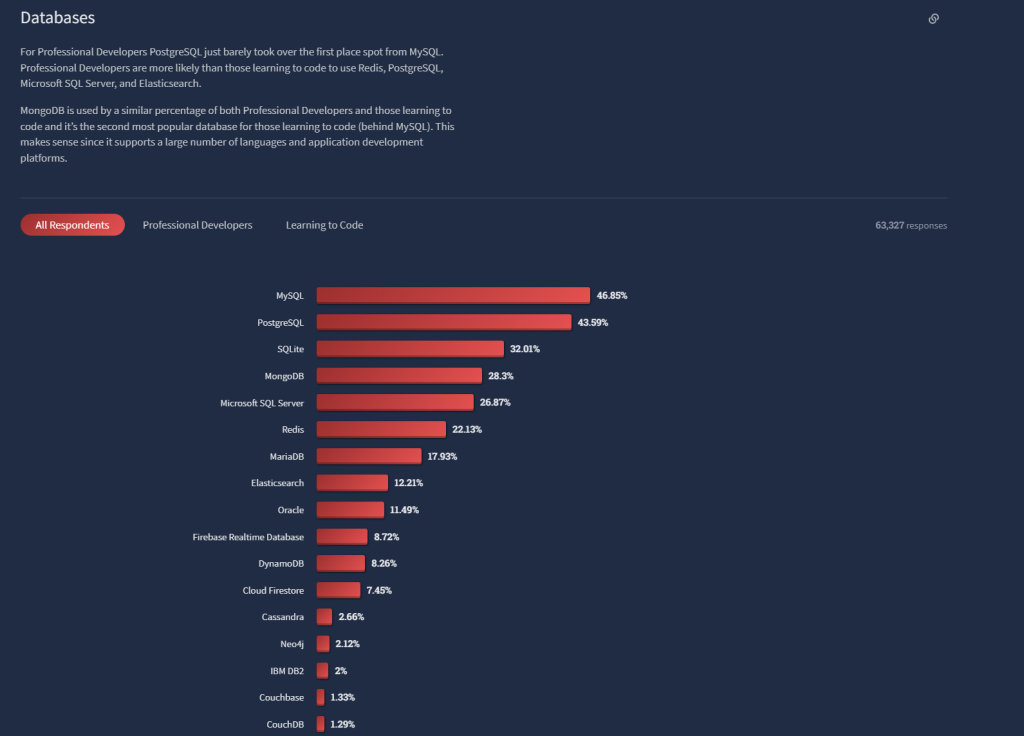
The performance and cost benefits to the business were plain to see in moving to an in-memory cache. Developers are paying attention and the recent (2022) Stack Overflow Developer Survey clearly shows the popularity of NoSQL and in-memory caches.
Architecture Can Evolve

Architectures can indeed evolve and hence it’s demo time. Let’s make this real and we are going to build an application. This application is going to illustrate we can deliver the same functionality, and same business outcome in multiple different ways, all with very different cost profiles. This application I am calling ‘Toilet Finder’. I will be using different types of compute but leaving the MySQL database as a constant.
In Australia, the Australian Government publishes a dataset of all the public toilets in Australia (https://data.gov.au/data/dataset/national-public-toilet-map) which includes various properties such as location, number or toilets, baby change tables and so on. This dataset is a CSV that contains 18,408 records (2022) and we are going to create a microservice that when presented with a postcode (querystring) it will return a JSON payload of all of the public toilets for that postcode.

Before we look at our deployment topologies, let’s take a look at the Python code in which we will be executing. This is a very simple snippet of code, it makes use of the built-in webserver in Python called Bottle. There is a route for /postcode and some basic validation to check if the postcode is 4 digits long.
import os
import mysql.connector
import json
import string
from bottle import route, run, template
@route('/')
def index():
return 'Hello World'
@route('/postcode/<postcode>')
def postcode(postcode):
returnData = "INVALID input"
#Validate input - can only be 4 numerics
if len(postcode) == 4 and postcode.isdigit():
#MYSQL Connection
cnx = mysql.connector.connect(user='xxxxxx@toilet-mysql', password='xxxxxxxxx',
host='toilet-mysql.mysql.database.azure.com',
database='toiletdata')
#Query
cursor = cnx.cursor()
query = ("SELECT name, address1, town FROM toilets "
"WHERE postcode=" + postcode)
cursor.execute(query)
resultRow = ""
for (name, address1, town) in cursor:
resultRow = resultRow + json.dumps({'name' : name, 'address1': address1, 'town': town}) + ","
resultRow = resultRow.rstrip(",")
cursor.close()
cnx.close()
returnData = "[" + resultRow + "]"
return returnData
#print __name__
if __name__ == '__main__':
port = int(os.environ.get('PORT', 8080))
run(host='0.0.0.0', port=port, debug=True)
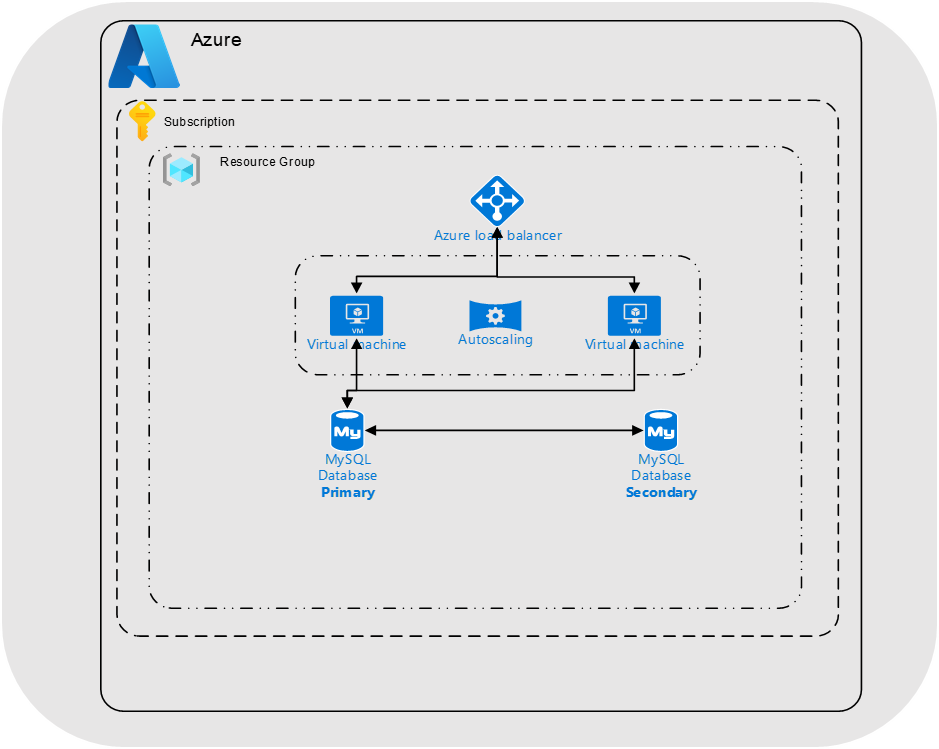
Typical VM Deployment
The picture below depicts how you could deploy this solution using VM’s. As we want this to be reliable, we will need to use multiple VM’s in a VM Scale Set / Auto Scaling Group and even using modest B2Ms (2vCPU) burstable instances my monthly compute cost will be $154USD (December 2022 / Australia-East).
This topology whilst being scalable, reliable and familiar to operate is storage and operationally heavy. I still need to patch and manage servers.
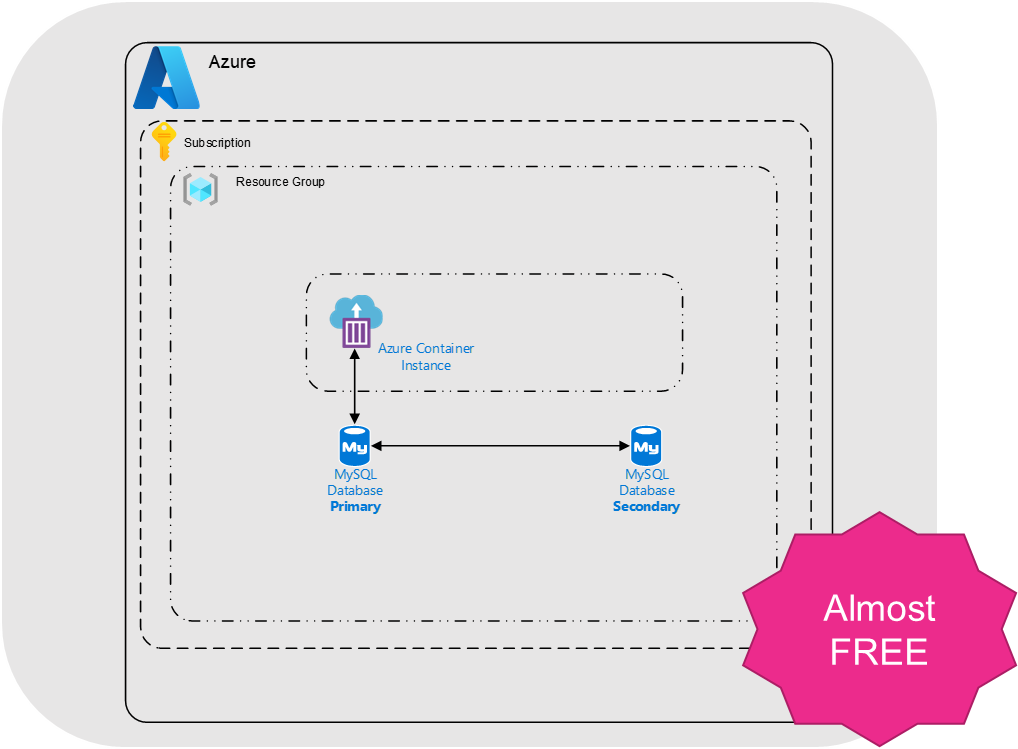
Container Deployment
The picture below depicts how you could deploy this solution using Containers. Evolving from our VM’s we are going to realise faster scale-up and scale-downs. It is going to be reliable and its a container. I am using Azure Container Instances where I will pay based on my consumption. I no longer need to maintain and manage Virtual machines but instead I use a docker file which states how to build my containers. I am hosting this in Azure Container Registry which is executed by Azure Container Instances.
FROM python:3.8
RUN mkdir /code
ADD requirements.txt /code/
ADD application.py /code/
ADD bottle.py /code/
RUN pip3 install bottle
RUN pip3 install mysql-connector
WORKDIR /code
EXPOSE 8080
CMD python /code/application.py
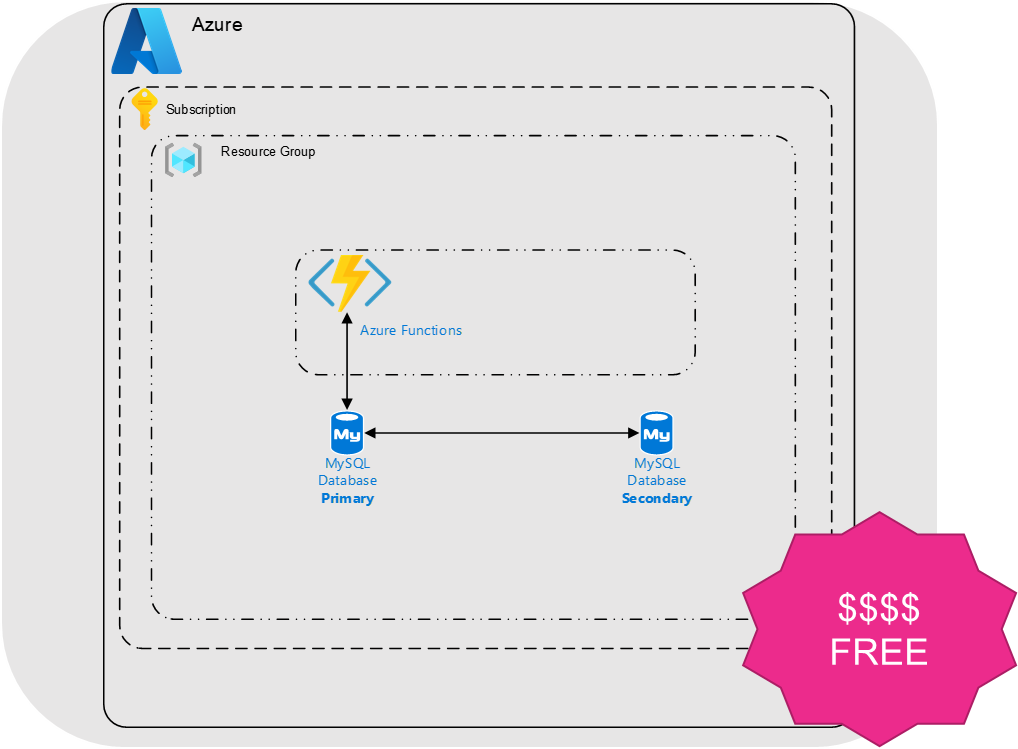
Functions and Event Driven Architecture
The picture below depicts how you could deploy this solution using Azure Functions and is similar if you are using AWS Lambda. Like our container offering, this is light weight, requires no patching of servers and given our modest load, fits within the free tier.
Worth noting, there will be a first hit / cold start penalty in which you can see in the demo below, which really isn’t an issue for workloads with consistent traffic profiles.
Video Demonstration
In the unrated video below, you will see a demonstration of all 3 methods of being able to deliver the same business outcome at 3 very different cost profiles. VM’s, Containers, Functions, all provide you as builders methods to create the same outcomes but I want you to think about the economy of your architecture, is this top of your mind?
Summary – Economy, The Next Dimension Of Cloud Architecture
As I close out this multi-part series I want you to realise you should be demanding the same or better outcome at lower cost.
Architectures should evolve during the lifetime of a system and radical changes are possible, driven by economics (Transition cost + operational cost).
Public cloud brings a magnitude of opportunities to builders and architects. Are you looking for the pots of gold? They are there with a raft of new levers that you can pull, twist, pull to architect for the new world.
Climb the cloud maturity curve and achive the same or better outcome at a lower cost.
Architectures can evolve, but it needs to make sense and with new tools and levers being released daily, the cost to change is only reducing.
Thanks
Shane Baldacchino.
Shane,
Great explanation of why architecture matters and how moving to cloud can be made cost effective!!!
Thanks,
DJ
Thanks DJ, appreciate the comment. Cloud and open source is ushering in new tools, we need to use them to real bring a step change in terms of efficiency.
Good to hear from you.
Shane
Even if it is not practical to exploit given the limitation to 4 digits, this code example contains an SQL injection in the postcode parameter.
Even simple code posted as an example like this one should be free of common vulnerabilities
– should anyone copy&paste that for further development
– to help raise awareness in developers
Thanks for the comment. I 100% agree. I qm away on leave, but me let me address this code in the coming week.
Shane
Viewing this “database” size I would remove the MySQL DB to use something else or even load csv in function. File size should not be that big.
Absolutely, in this example a flat file would have worked just fine. Perhaps even a noSQL as the records increase. Thanks JB.
Shane